
Language
Python
Tool Type
Algorithm
License
The MIT License
Version
0.0.5
Head of Cabinet of Ministers

Textar is a set of Python algorithms designed to consolidate natural language processing (NLP) tools used by the National Directorate of Public Information and Data of Argentina. This tool makes it easy to search and categorize questions for government reporting. Developed to assist in the preparation of reports and resolve specific questions, Textar improves efficiency in the management of government questions, avoiding duplication and categorizing by topic. These algorithms are a fundamental part of an internal interface that optimizes the integration and communication of information.
Textar solves the problem of managing large volumes of questions and data within government offices, simplifying the search and categorization of information, which is crucial for efficient reporting and internal communication.
Text analysis and classification. Retrieval of similar texts. Utilization of machine learning algorithms. Integration with Python data science stack.
Built on Python as the core language, leveraging its versatility and efficiency. Integrates open-source libraries such as pandas, numpy, scikit-learn, and scipy for data analysis, machine learning, and scientific computations. Adopts the MIT license to promote openness and collaboration in development. Facilitates interoperability and the use of open data formats to maximize accessibility and information reuse.
Connect with the Development Code team and discover how our carefully curated open source tools can support your institution in Latin America and the Caribbean. Contact us to explore solutions, resolve implementation issues, share reuse successes or present a new tool. Write to [email protected]
This image displays a documentation page for 'Text Analyzer', a Python package for text analysis, classification, and recovery, with a 68% coverage status and MIT license.
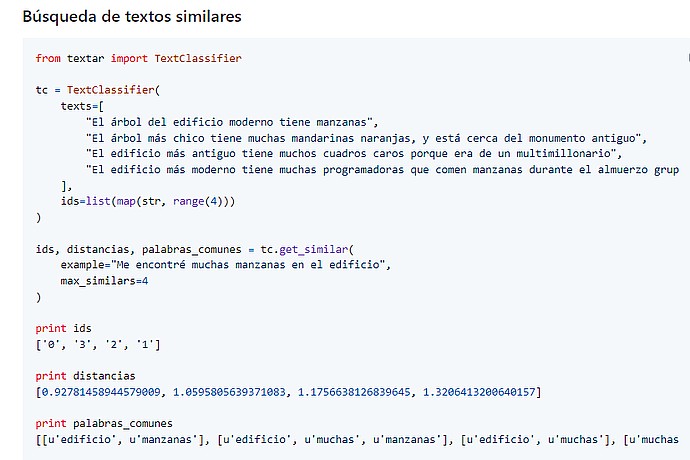
Python code using "textar" library. Defines texts and finds similarities with "I found many apples in the building". Shows IDs, distances: [0.9278, 1.0595, 1.1756, 1.3206], and common words like 'building' and 'apples'.
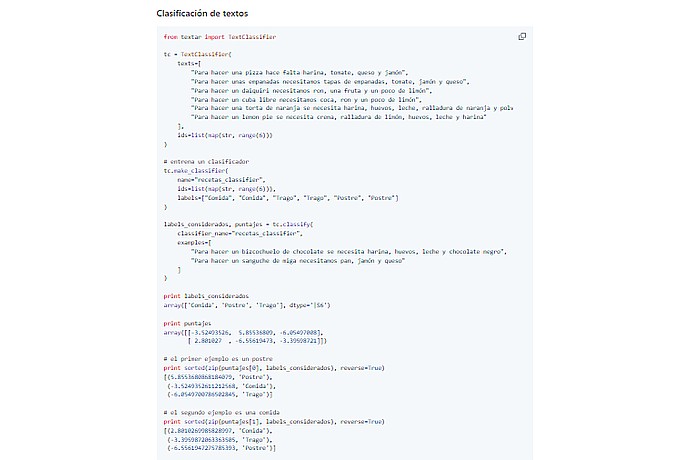
This image shows Python code for text classification using the TextBlob library. It includes data preparation, classifier training, and printing classification probabilities and labels.
Explains its application in legislative opening and automation
Technical details on how TextAr works
Article on the use of NLP in governments, includes TextAr
Information on tools related to open data