
Idioma
Python
Tipo de herramienta
Algoritmo
Licencia
The MIT License
Versión
0.0.5
Jefatura de Gabinete de Ministros

Textar es un conjunto de algoritmos de Python diseñados para consolidar las herramientas de procesamiento de lenguaje natural (PLN) utilizadas por la Dirección Nacional de Información y Datos Públicos de Argentina. Esta herramienta facilita la búsqueda y categorización de preguntas para la elaboración de informes gubernamentales. Desarrollada para asistir en la elaboración de informes y resolver dudas específicas, Textar mejora la eficiencia en la gestión de preguntas gubernamentales, evitando duplicaciones y categorizando por tema. Estos algoritmos son una parte fundamental de una interfaz interna que optimiza la integración y comunicación de la información.
Textar soluciona el problema de gestionar grandes volúmenes de preguntas y datos dentro de oficinas gubernamentales, simplificando la búsqueda y categorización de información, lo que resulta crucial para la elaboración eficiente de informes y la comunicación interna.
Análisis de texto y clasificación. Recuperación de textos similares. Utilización de algoritmos de aprendizaje automático. Integración con Python Data Science Stack.
Implementa Python como lenguaje base, aprovechando su versatilidad y eficiencia. Integra bibliotecas de código abierto como pandas, numpy, scikit-learn y scipy para análisis de datos, aprendizaje automático y cálculos científicos. Adopta la licencia MIT para promover la apertura y colaboración en el desarrollo. Facilita la interoperabilidad y el uso de formatos de datos abiertos para maximizar la accesibilidad y reutilización de la información.
Conéctese con el equipo de Código para el Desarrollo y descubra cómo nuestras herramientas de código abierto, cuidadosamente curadas, pueden apoyar a su institución en América Latina y el Caribe. Escríbanos para explorar soluciones, resolver dudas de implementación, compartir éxitos de reutilización o presentar una nueva herramienta. Escríbenos a [email protected]
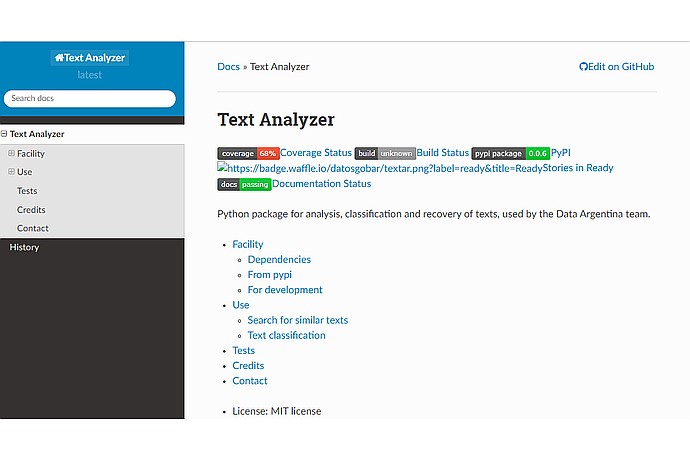
Esta imagen muestra una página de documentación para 'Text Analyzer', un paquete de Python para análisis, clasificación y recuperación de texto, con un estado de cobertura del 68% y una licencia MIT.
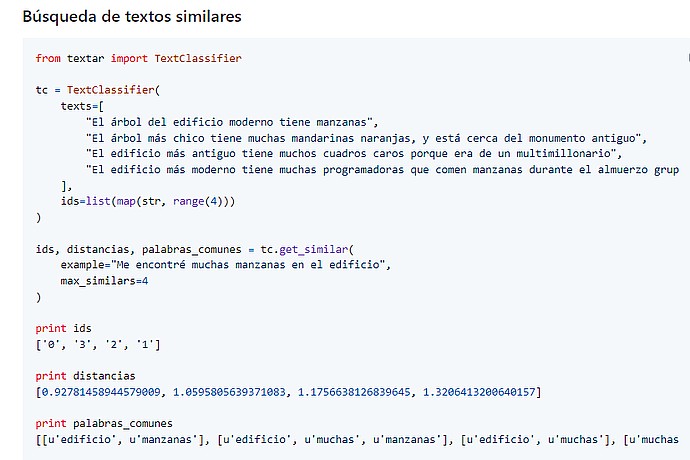
Código en Python usando la biblioteca "textar". Define textos y busca similitudes con "Me encontré muchas manzanas en el edificio". Muestra IDs, distancias: [0.9278, 1.0595, 1.1756, 1.3206], y palabras comunes como 'edificio' y 'manzanas'.
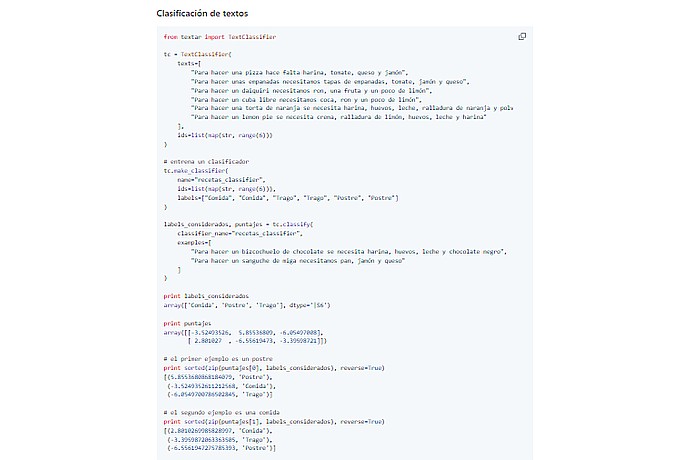
Esta imagen muestra el código Python para la clasificación de texto utilizando la biblioteca TextBlob. Incluye la preparación de datos, la capacitación del clasificador y las probabilidades de clasificación de impresión y las etiquetas.
Explica su aplicación en apertura y automatización legislativa
Detalles técnicos sobre cómo funciona TextAr
Artículo sobre uso de PLN en gobiernos, incluye TextAr
Información sobre herramientas relacionadas con datos abiertos